
On 13 May 2025, the EDI Caucus hosted a seminar in our series Innovative Approaches to Research in Equity, Diversity & Inclusion. The title was “Using AI to Transform EDI Research”, presented by Dr Lukas Kikuchi and Sean Greaves of the Autonomy Institute. The Autonomy Institute is an independent progressive research organisation based in London. They’ve worked on concepts such as the 4-day working week and the universal basic income. Autonomy are co-investigators of the EDI Caucus and they particularly work in workstream 3 which is looking at enabling workspaces.
Lukas is head of the Autonomy Data Unit, which supports with bespoke technical work for other progressive organisations. They produce tools for the in-house policy team and consultancies, but also for external organisations. One example is the tool, Scribe, which Lukas and Sean presented in the seminar.
Scribe is a tool not yet available to the public. Scribe is “a methodology or a tool that we’ve applied a few times inside Autonomy, and it’s an AI tool to deal with large sets of free-form text survey responses.” Autonomy uses AI a lot in their practice. Over time they have “developed an approach to AI that tries to exploit all its capabilities whilst also remaining cautious of the AI hype bubble.”
Autonomy have developed its AI tools with a view to three principles:
- The idea of lossless processing. To summarise text without losing access to the original source material. “As much as possible, we don’t transform at all, we just use AI to organise and categorise the original data.”
- To use AI to enhance the human researcher. While AI can be used for cost-cutting, Autonomy are more interested in using AI to do things not possible before. With Scribe, it is using AI to handle large-scale survey processing usually feasible only by using a lot of human resource. It enables collecting free-text survey responses as opposed to multiple-choice type responses. “We’re all about enhancing the human researcher in a specific research stream using AI, but we don’t want to use AI to do the research for us.”
- To leverage “mediocre computing”. Autonomy doesn’t want to use AI for complex reasoning or judgement, instead using AI where it can be reliable with simple tasks but at scale – e.g. rephrasing of sentences and summarising.
What is Scribe?
So far, Autonomy has used Scribe to organise and cluster large volumes of unstructured text stemming from surveys, interviews and consultations. Scribe is used to track emergent themes from the various voices inside those bodies of text and then quantify the qualitative patterns, whilst also preserving access to the original source text. Scribe produces a first draft analysis, or a first reorganisation of the survey responses, and then a human researcher looks at the survey responses, maybe adjusting some responses that were misclassified. Scribe gets 90% of the work done, but the researcher does the final and most important last 10%.
In Autonomy’s research on the shorter working week, they’ve conducted exit surveys. Originally the responses were completely categorical. E.g. “How did you enjoy the 4-day working week?” Options available were “I really liked it” “I liked it”, “Neutral” – etc. Such kinds of question can be leading, or they put words into the respondent’s mouth. Scribe enables surveys to accept free-form text, gathering more rich, nuanced data in response. “Scribe allows you to sift through this and see what are the unique insights and … the intersectional insights. Potentially Scribe may also, with some adjustments of the methodology, help us to surface marginalised voices.”
Scribe uses “embeddings” and LLMs (large language models). Scribe takes three steps. Firstly, it takes potentially quite long text responses and splits them up into several small responses. Someone may respond to a question with several sentences of what a 4-day working week means to them. Scribe breaks these down into discrete sentences. This step is optional; a researcher might want to run the results with and without this split, and see the difference.
The second step clusters and categorises responses by semantic proximity. If two statements are similar, they’re clustered into the same category. “The key tech we use to do this is by converting the text to what’s called an ‘embedding’, which is a sort of mathematical representation of the meaning of the text.” Lukas explained, “two sentences that might be called semantically identical would be ‘she gave the book to her friend’ and ‘her friend received the book from her’. …Two sentences can be semantically similar if it’s slightly different, but it’s roughly saying the same thing. ‘She handed over a book as a gift to her friend’ is roughly the same as ‘her friend ended up with the book she gave’.”
Once responses are clustered, each cluster is then summarised using an LLM, giving a broad overview of what responses think about a particular topic. E.g. all responses touching on work/life balance are clustered, and most people think their work/life balance has improved with the 4-day working week, but a couple of people found it did not improve but did not worsen.
Visually, this is displayed using coloured dots clustering against a white background:
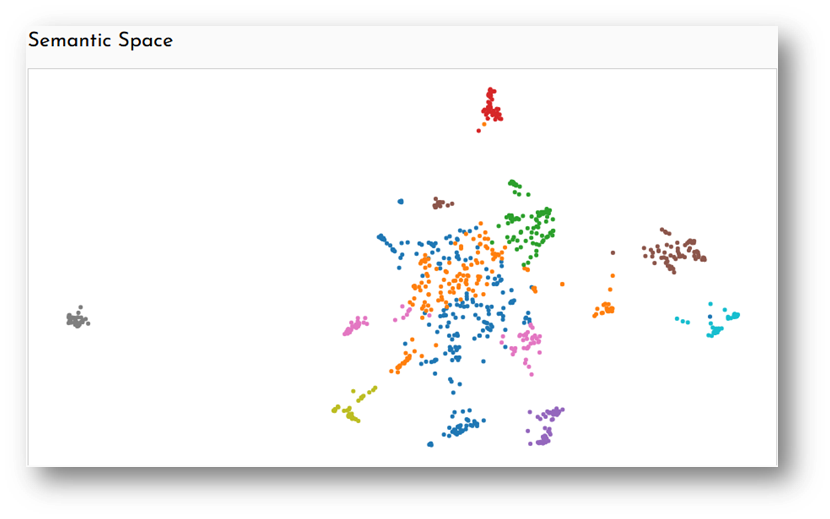
“Each of these dots is a response and the distance between any of these two points is an indication of the semantic similarity of the responses. If two dots aka responses are close to each other, that means they roughly contain the same semantic content.” Sean later explained during the demo of the tool, “By being able to see which dots correspond to each response or statement you get a sense of what semantic space means and build a bit of intuition.”
As one hovers the curser over a dot, it displays the data for one survey response. The information includes the original text of the response and the metadata of the recipient – e.g. gender, ethnicity, disability, etc, depending on what the survey asked. This metadata can be detailed or broad, based on the survey’s design. Lukas also explained that a research team could even use open-text boxes for people to describe their gender and ethnicity, and this, too, could be categorised by Scribe.
Each topic – displayed by one colour of dots – is then summarised by Scribe, using the LLM. Stats are visible alongside the summary – e.g. 83 respondents, 32% of total respondents, mentioned ‘an increase in efficiency and rigor at work’. The clustering and summarising is not foolproof – it may need to be adjusted by the researcher. But it enables a researcher to condense thousands of individual text responses into 12 or 15 or so groups to be further studied.
Why use Scribe instead of ChatGPT? Firstly, to use AI in a controlled setting. “We prefer having a pipeline where we send individual questions to the AI with the right context. It just gives us more control to calibrate the procedure.” Secondly, there’s a limit to how much data can be put into ChatGPT, so it won’t scale infinitely. Thirdly, the clustering based on semantic similarity isn’t something ChatGPT can do. Scribe is a pipeline of a series of steps using various AI methods. We’ve built the pipeline to have a bit more control and also quality assurance of the actual thing we’re doing. It’s also so that we can see original data. It gives us control of how we present the data and making sure the original stuff is there as well.”
Once researchers have read through all the responses, that’s not going to be the only time that they look at those responses. They will be doing multiple passes over the data as they attempt to taxonomise it to find the key findings. Scribe makes it much easier to find common points of discussion that can help researchers when investigating this data and writing it up. Because of this increase in productivity, Scribe can lead to faster feedback loops for engagement, reducing analysis time from weeks to days or hours. “We can have a continuing process of survey sourcing and processing. We haven’t applied it for EDI as such, but …I think it can be adapted.”
Listening to marginalised voices
Scribe has a filter function based on the metadata of the survey. If, for example, the survey asked for gender, whether gender is same as sex at birth, disability, ethnicity and sexual orientation, it would enable the researcher to filter by ticking the relevant boxes. Once ticked, only those voices show on the dot map. From 10,000 responses, we could see what Black cis disabled women think. The same caution with identifiability would be needed as with usual survey research. This must be done by the human researcher.
In filtering by demographic data, Scribe is able to summarise the views of that demographic. E.g. 25% of Black cis disabled women (8 respondents out of 32) thought the 4-day working week improved their fitness and health; 75% (24 out of 32) of Black cis disabled women found it helped them in scheduling medical appointments.
Autonomy produced a report on the 4-day working week one year into the study, which can be found here: [https://autonomy.work/wp-content/uploads/2024/02/making-it-stick_-1.pdf] They used the Scribe methodology on survey responses, zooming into different minority demographics. The clusterings can be used in context with demographic data to look at what minority voices are saying.
Linking to other research
Scribe has been set up to link with Autonomy’s local database of research and reports. If, for example, a group of responses is on improved healthy lifestyle from the 4-day working week, it links to a previous piece of research Autonomy did on the 4-day working week in Iceland, where there’s a quote from a respondent talking about having more time to go out and do exercise. This linking could be expanded to a broader database of work, but so far Autonomy have just linked to their own body of work.
Availability of Scribe
For now, Scribe is an in-house tool and methodology used in its work with partners. They are open to starting a conversation with people on how they can use Scribe with others. “Down the line we might actually try to create some kind of public facing tool / user interfacing tool- so you go on a website and upload a thing. But we’re not quite there yet. The linked here roughly shows what that could look like, but it’s also very rough in its shape.” https://static.autonomy.work/adu/public/scribe-app/
This is a summary of an hour-long seminar. You can view the full recording by clicking here. You can read the full transcript by clicking here. And you can view the slides by clicking here.


Neurodiversity & Menopause at Work Seminar Recording
Published 15 Oct 2024
Watch/listen to a panel discussing neurodivergence & menopause.

Menstrual Health Top Tips
Published 8 March 2024
Download our poster on Menstrual Health at Work – Top Tips.

Peer Review Bias Seminar Recording
Published 23 April 2024
Watch/listen to a panel discussing peer review bias in the funding process.




































